


Содержание Показать
В современном мире, данные - это ценный ресурс, и одной из ключевых отраслей, которые осуществляют работу с данными, является Data Science. Спрос на специалистов в этой области по-прежнему растет, и многие компании размещают вакансии на популярных платформах, таких как HeadHunter. Но как находить и анализировать эти вакансии эффективно?
В этой статье мы рассмотрим, как создать парсер вакансий Data Science с hh.ru, используя их API.
Общие сведения о процессе извлечения информации (парсинг) о вакансиях на платформе hh.ru
Мы планируем осуществить парсинг вакансий из двух городов: Москвы и Санкт-Петербурга, поскольку именно в этих городах наиболее плотно сосредоточены вакансии в области Data Science.
Наши цели включают в себя сбор следующей информации о вакансиях: id, город, компания, отрасль, название вакансии, ключевые слова, навыки, требуемый опыт, зарплата и URL.
Наш алгоритм парсера будет следующим: мы начнем с отправки запросов к API HeadHunter для получения данных о вакансиях. Затем мы обработаем полученные данные и сохраним их в базу данных PostgreSQL. Для избежания дубликатов, мы будем удалять вакансии, основываясь на уникальности URL-адресов каждой вакансии. Это позволит нам сохранить только уникальные записи и обновлять данные, если появятся изменения в существующих вакансиях. При необходимости полного обновления таблицы, мы удалим существующую и создадим новую.
Таким образом, наша задача - автоматизировать сбор данных о вакансиях Data Science с двух ключевых городов, обеспечивая актуальность и целостность информации в нашей базе данных.
Получение токена API hh.ru
- Регистрация на HH.ru:Если у вас уже есть аккаунт на HH.ru, вы можете использовать его для доступа к API. Если нет, следуйте этим шагам:
- Перейдите на официальный сайт Head Hunter.
- Нажмите на "Войти" в правом верхнем углу страницы.
- Нажмите "Зарегистрироваться" и следуйте инструкциям для создания нового аккаунта.
- Создание приложения:После успешной регистрации и входа в свой аккаунт HH.ru, выполните следующие шаги для создания приложения и получения токена API:
- Перейдите на страницу для разработчиков HH.ru: https://dev.hh.ru/admin.
- Нажмите на "Создать приложение".
- Заполнение информации о приложении:Вам потребуется предоставить информацию о вашем приложении:
- Название приложения: Укажите уникальное имя вашего приложения.
- Описание приложения: Добавьте краткое описание цели вашего приложения.
- Сайт приложения: Если у вас есть веб-сайт для приложения, укажите его URL.
- Callback-URL: Оставьте это поле пустым, если не понимаете, зачем оно нужно.
- Получение токена:После создания приложения, вы будете перенаправлены на страницу настроек приложения. Здесь вы найдете раздел "Доступы", где будет отображен ваш токен API hh.ru.
- Нажмите на "Показать" рядом с полем "Токен доступа к API".
- Токен будет отображен на экране. Обязательно скопируйте его в безопасное место, так как он не будет отображаться снова.
Теперь у вас есть токен API hh.ru, который вы можете использовать для доступа к данным на сайте hh.ru. Обратите внимание, что этот токен предоставляет доступ к вашему аккаунту, поэтому обрабатывайте его как конфиденциальную информацию и не распространяйте его публично.
Аренда и настройка базы данных PostgreSQL для хранения данных о вакансиях
Этот этап довольно прост и понятен: я планирую арендовать базу данных PostgreSQL от провайдера Timeweb Cloud, который является самым бюджетным вариантом. Нам подойдет объем базы данных в 8 ГБ.
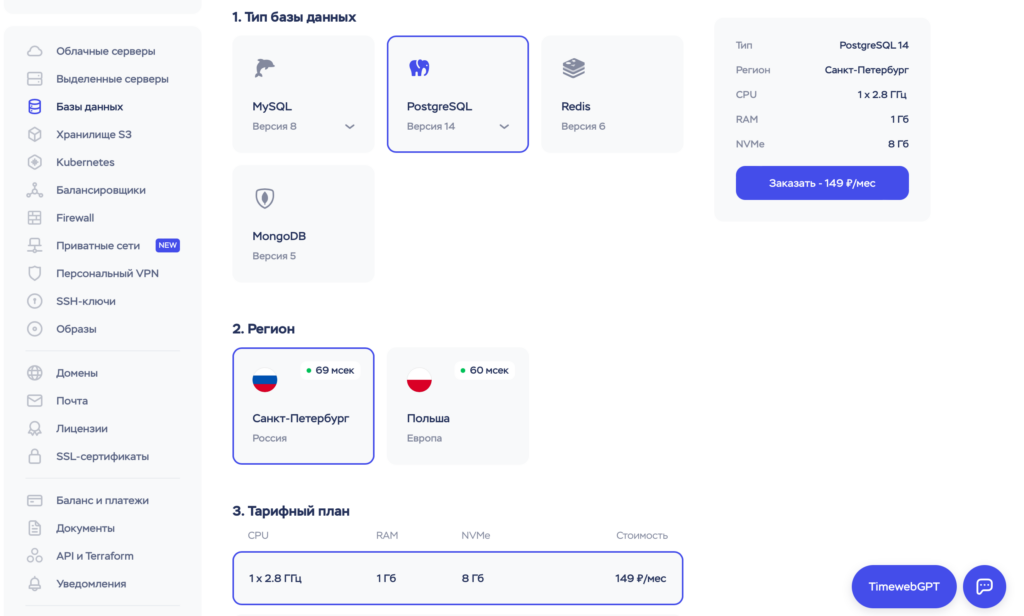
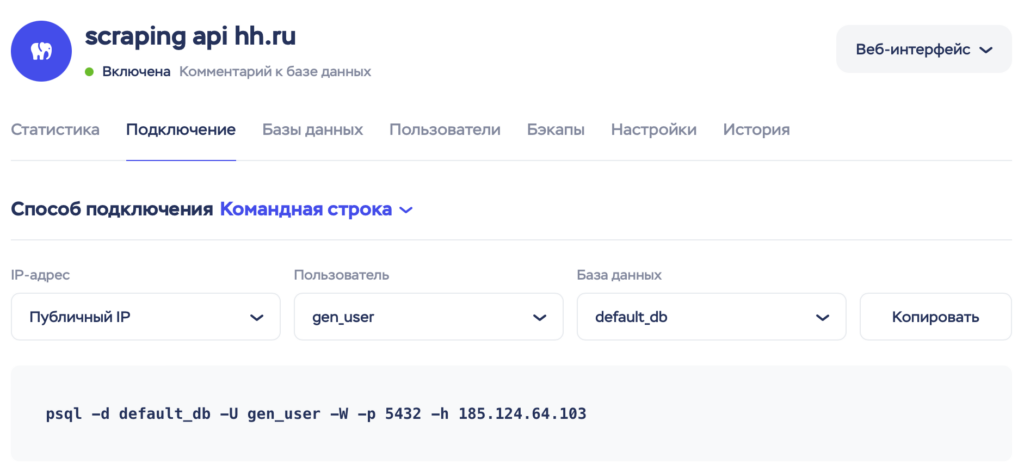
И теперь, когда у нас есть все необходимое для парсинга вакансий, мы пишем код...
Пишем код
Установка необходимых библиотек
Для начала парсинга вам понадобятся следующие библиотеки:
import time
import random
import logging
import requests
import psycopg2
import scheduletime - для работы с временем. random - для создания случайных задержек между запросами и избегания блокировки. logging - для ведения журнала событий. requests - для отправки HTTP-запросов к API hh.ru. psycopg2 - для взаимодействия с базой данных PostgreSQL, в которой будут сохраняться данные о вакансиях. schedule - для планирования регулярного запуска парсинга.
Конфигурация базы данных и API hh.ru
Для начала работы нам нужно установить токен API HeadHunter. Этот токен будет использоваться для доступа к данным на сайте HeadHunter.
# Установка токена API HeadHunter
hh_api_token = 'ETBWRT4345GTRFVF0HUBRADM745OIKD392VU7155JO'Для хранения собранных данных о вакансиях мы должны настроить базу данных PostgreSQL. В конфигурации базы данных указаны параметры, такие как имя базы данных, имя пользователя, пароль, хост и порт, необходимые для соединения с базой данных.
# Конфигурация базы данных
db_config = {
'dbname': 'default_db',
'user': 'gen_user',
'password': 'baza_data',
'host': '185.124.64.103',
'port': '5432'
}Также настроим логирование:
# Настройка логирования
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')Функция для создания таблицы
Теперь необходимо создать базу данных с таблицей "vacancies" в соответствии с настройками, предоставленными в конфигурации. Для этого мы используем функцию create_table:
# Функция для создания таблицы vacancies
def create_table(conn):
cursor = conn.cursor()
create_table_query = """
CREATE TABLE IF NOT EXISTS vacancies (
id SERIAL PRIMARY KEY,
city VARCHAR(50),
company VARCHAR(200),
industry VARCHAR(200),
title VARCHAR(200),
keywords TEXT,
skills TEXT,
experience VARCHAR(50),
salary VARCHAR(50),
url VARCHAR(200)
)
"""
cursor.execute(create_table_query)
conn.commit()
cursor.close()
logging.info("Таблица 'vacancies' успешно создана.")Функция для удаления таблицы
Удаление таблицы после каждого запуска парсера имеет вполне логичное объяснение: парсер собирает новые данные о вакансиях ежедневно, и создание новой таблицы каждый день предотвращает потерю данных в случае возникновения ошибок в процессе сбора или обработки информации, а также обеспечивает чистоту и актуальность данных в базе.
# Функция для удаления таблицы vacancies
def drop_table(conn):
cursor = conn.cursor()
drop_table_query = "DROP TABLE IF EXISTS vacancies"
cursor.execute(drop_table_query)
conn.commit()
cursor.close()
logging.info("Таблица 'vacancies' успешно удалена.")Функция для получения вакансий
# Функция для получения вакансий
def get_vacancies(city, vacancy, page):
url = 'https://api.hh.ru/vacancies'
params = {
'text': f"{vacancy} {city}",
'area': city,
'specialization': 1,
'per_page': 100,
'page': page
}
headers = {
'Authorization': f'Bearer {hh_api_token}'
}
response = requests.get(url, params=params, headers=headers)
response.raise_for_status()
return response.json()# Функция для получения навыков вакансии
def get_vacancy_skills(vacancy_id):
url = f'https://api.hh.ru/vacancies/{vacancy_id}'
headers = {
'Authorization': f'Bearer {hh_api_token}'
}
response = requests.get(url, headers=headers)
response.raise_for_status()
data = response.json()
skills = [skill['name'] for skill in data.get('key_skills', [])]
return ', '.join(skills)Функция для получения отрасли компании
# Функция для получения отрасли компании
def get_industry(company_id):
# Получение отрасли компании по ее идентификатору
if company_id is None:
return 'Unknown'
url = f'https://api.hh.ru/employers/{company_id}'
response = requests.get(url)
if response.status_code == 404:
return 'Unknown'
response.raise_for_status()
data = response.json()
if 'industries' in data and len(data['industries']) > 0:
return data['industries'][0].get('name')
return 'Unknown'Функция для парсинга вакансий
# Функция для парсинга вакансий
def parse_vacancies():
cities = {
'Москва': 1,
'Санкт-Петербург': 2
}
vacancies = [
'BI Developer', 'Business Development Manager', 'Community Manager', 'Computer vision',
'Data Analyst', 'Data Engineer', 'Data Science', 'Data Scientist', 'ML Engineer',
'Machine Learning Engineer', 'ML OPS инженер', 'ML-разработчик', 'Machine Learning',
'Product Manager', 'Python Developer', 'Web Analyst', 'Аналитик данных',
'Бизнес-аналитик', 'Веб-аналитик', 'Системный аналитик', 'Финансовый аналитик'
]
with psycopg2.connect(**db_config) as conn:
drop_table(conn)
create_table(conn)
for city, city_id in cities.items():
for vacancy in vacancies:
page = 0
while True:
try:
data = get_vacancies(city_id, vacancy, page)
if not data.get('items'):
break
with conn.cursor() as cursor:
for item in data['items']:
if vacancy.lower() not in item['name'].lower():
continue # Пропустить, если название вакансии не совпадает
title = f"{item['name']} ({city})"
keywords = item['snippet'].get('requirement', '')
skills = get_vacancy_skills(item['id'])
company = item['employer']['name']
industry = get_industry(item['employer'].get('id'))
experience = item['experience'].get('name', '')
salary = item['salary']
if salary is None:
salary = "з/п не указана"
else:
salary = salary.get('from', '')
url = item['alternate_url']
insert_query = """
INSERT INTO vacancies
(city, company, industry, title, keywords, skills, experience, salary, url)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
cursor.execute(insert_query,
(city, company, industry, title, keywords, skills, experience, salary, url))
if page >= data['pages'] - 1:
break
page += 1
# Задержка между запросами в пределах 1-3 секунд
time.sleep(random.uniform(3, 6))
except requests.HTTPError as e:
logging.error(f"Ошибка при обработке города {city}: {e}")
continue # Перейти к следующему городу, если произошла ошибка
conn.commit()
logging.info("Парсинг завершен. Данные сохранены в базе данных PostgreSQL.")Добавляем функцию для удаления дубликотов на основе столбца «url»
# Функция для удаления дубликотов на основе столбца «url»
def remove_duplicates():
with psycopg2.connect(**db_config) as conn:
cursor = conn.cursor()
# Удалить дубликаты на основе столбца «url»
delete_duplicates_query = """
DELETE FROM vacancies
WHERE id NOT IN (
SELECT MIN(id)
FROM vacancies
GROUP BY url
)
"""
cursor.execute(delete_duplicates_query)
conn.commit()
cursor.close()
logging.info("Дубликаты в таблице 'vacancies' успешно удалены.")Функция для запуска парсинга
def run_parsing_job():
logging.info("Запуск парсинга...")
try:
parse_vacancies()
remove_duplicates()
except Exception as e:
logging.error(f"Ошибка при выполнении задачи парсинга: {e}")Чтобы скрипт запускался в 12:00 по МСК каждый день используем библиотеку schedule:
# Планировщик задач
schedule.every().day.at("12:00").do(run_parsing_job)
while True:
schedule.run_pending()
time.sleep(1)Запуск парсера
В этой части статьи мы изучим, как начать использовать парсер. Вы можете выполнить запуск парсера на своем компьютере, предварительно установив все необходимые библиотеки. Также, вы можете развернуть парсер на виртуальной машине, где он будет функционировать автономно. В моем случае, я планирую запустить парсер на облачном сервере Timeweb Cloud.
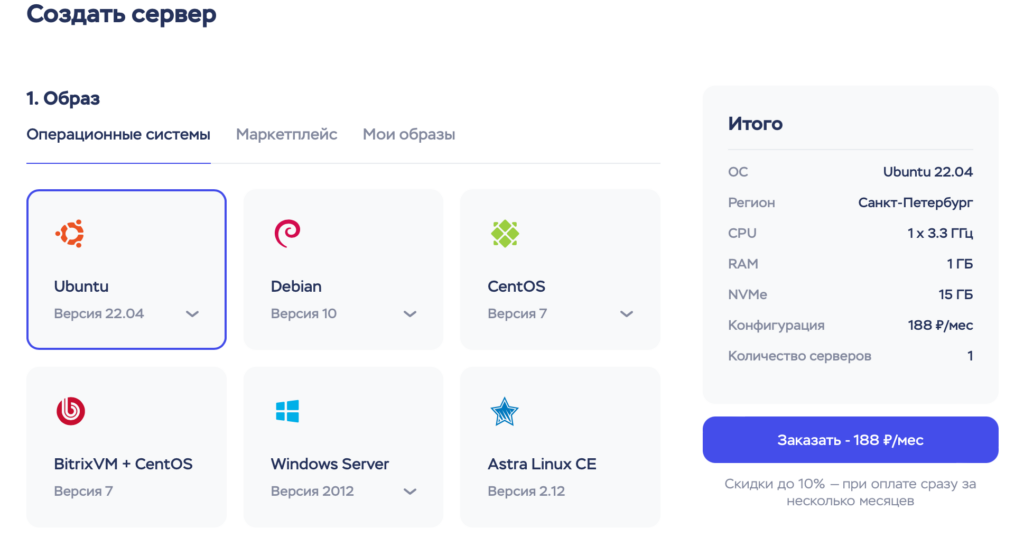
Затем, следует установить соединение с сервером с использованием FTP (в данном случае, это FileZilla), и на сервере создать новую папку с названием "HeadHunter". Далее, переместите ваш Python-скрипт в эту новую папку.
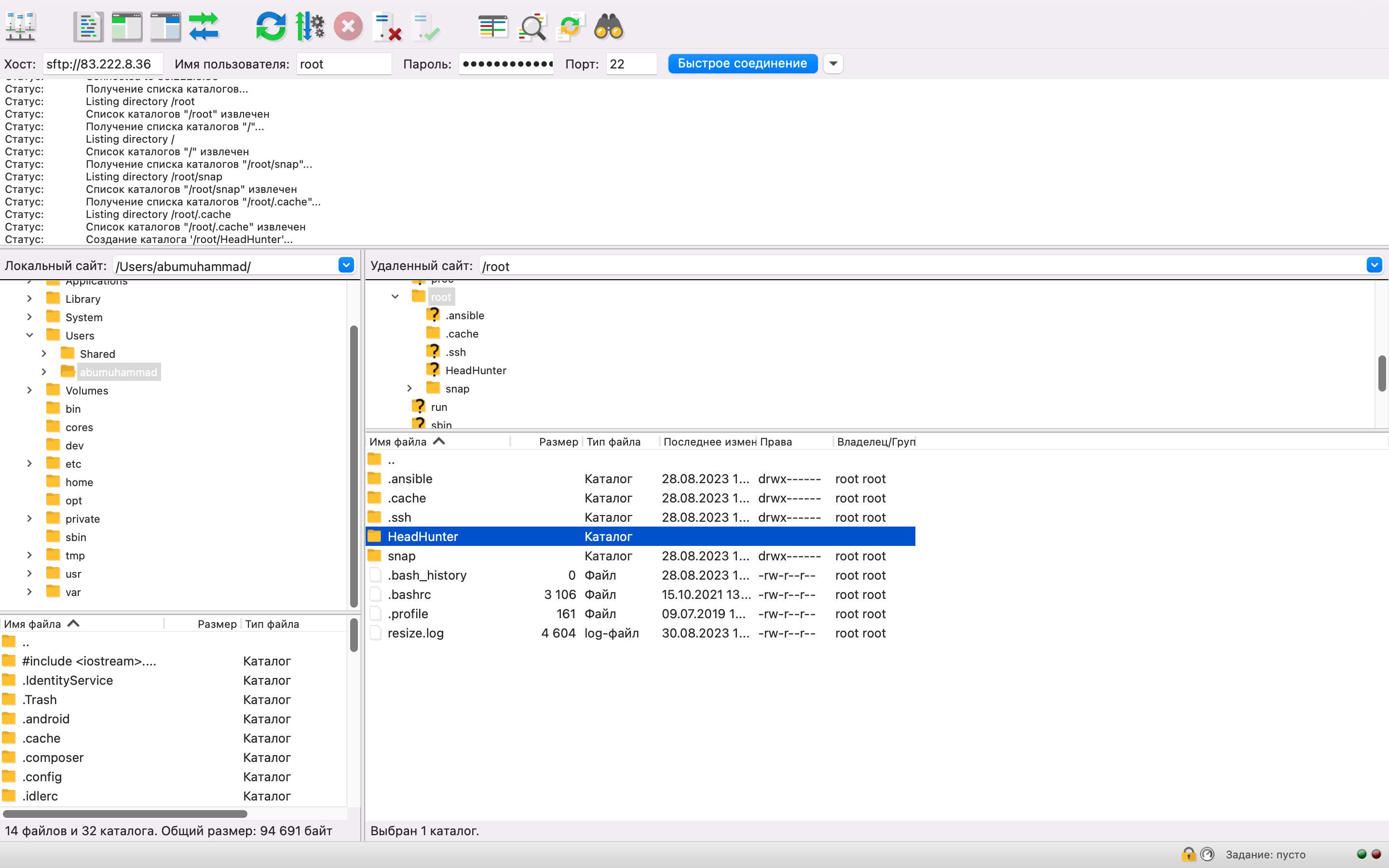
Далее, мы устанавливаем SSH-соединение с сервером с помощью терминала.
zurab@MacBook-Air ~ % ssh root@83.222.8.36
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
root@83.222.8.36's password:
# далее вводим парольИ выполняем по порядку данные команды
sudo apt update
sudo apt upgrade# Устанавливаем Python
sudo apt install python3
sudo apt install python3-pip# Устанавливаем необходимые библиотеки
pip install logging
pip install requests
pip3 install psycopg2-binary
pip install schedule# Переходим в папку HeadHunter
cd HeadHunter# Запускаем скрипт
python3 main.pyПослесловие
В заключение, парсинг вакансий — это мощный инструмент для исследования рынка труда, нахождения лучших вакансий и анализа требований работодателей. Независимо от того, где вы запускаете свой парсер — на своем компьютере, виртуальной машине или облачном сервере, важно помнить, что у вас есть множество инструментов и ресурсов, чтобы успешно справиться с этой задачей.
Помимо технической стороны, не забывайте о законности и этике парсинга данных, учитывайте условия использования API и соблюдайте правила сайта, с которого вы собираете информацию.
Надеемся, что данная статья стала для вас полезным ресурсом и вдохновила на дальнейшие исследования и автоматизацию процесса поиска работы или анализа рынка труда. Помните, что мир данных и возможностей бескрайний, и ваша преданность достижению целей сделает вас успешным и уверенным в использовании парсинга в вашей работе. Успехов вам!
 помощник
помощник