


Содержание Показать
Будущее — это худшая из всех абстракций. Будущее никогда не приходит таким, каким его ждёшь. Не вернее ли сказать, что оно вообще никогда не приходит?
Если ждёшь А, а приходит Б, то можно ли сказать, что пришло то, чего ждал? Всё, что реально существует, существует в рамках настоящего.

Временной ряд?
Временной ряд
Первое формальное определение временных рядов сводится к тому, что это последовательность чисел, где каждый элемент связан с определенным моментом времени и между которыми может существовать взаимосвязь. Частота этих наблюдений может быть разной, но суть остаётся прежней — это последовательность значений, полученных с течением времени.
Второе определение более теоретическое и опирается на моделирование. Оно рассматривает временные ряды как последовательности случайных величин. На практике, в данных у нас всегда есть конечное число наблюдений: [math]\left( y_t \right)_{t=1}^{T}[/math]. Однако с точки зрения модели, временной ряд может быть потенциально бесконечным как в одном направлении [math]\left( y_t \right)_{t=1}^{\infty}[/math] , так и в обоих направлениях [math]\left( y_t \right)_{t=-\infty}^{t=+\infty}[/math].
Таким образом, временной ряд — это последовательность наблюдений, измеренных через равные или неравные промежутки времени. И основная особенность временных рядов в том, что прошлые данные помогают предсказать будущее, в отличие от классического анализа, где наблюдения считаются независимыми и одинаково распределёнными.
И прежде чем углубляться в анализ временных рядов, думаю, будет полезно освежить в памяти основные математические обозначения, которые используются при работе с ними. Так что, смотри под кат ⬇️
Базовые математические обозначения для работы
с временными рядами
1. Текущий момент времени — это просто [math]t[/math]. Например, сегодня — это [math]t[/math].
2. Значение в момент времени [math]t[/math] — это [math]y_t[/math]. Если ты записываешь температуру сегодня, то значение температуры будет [math]y_t[/math].
3. Прошлое — обозначается как [math]t-1, t-2, \dots[/math]. Если ты хочешь обратиться ко вчерашнему дню, то это будет [math]t-1[/math], а температура вчера — [math]y_{t-1}[/math]. Позавчера — [math]t-2[/math], и температура позавчера — [math]y_{t-2}[/math].
4. Будущее — обозначается как [math]t+1, t+2 \dots[/math]. Если ты хочешь говорить о прогнозе на завтра, это будет [math]t+1[/math], а прогноз температуры на завтра — [math]y_{t+1}[/math].
Пример:
- Температура позавчера: [math]y_{t-2}[/math]
- Температура сегодня: [math]y_t[/math]
- Прогноз на завтра: [math]y_{t+1}[/math]
Прогнозы
Когда мы делаем прогноз, мы используем специальное обозначение для прогноза на будущее:
$$\hat{y}_{t+h}$$Здесь:
- [math]t[/math] — это текущий момент.
- [math]h[/math] — это шаг в будущее. Например, если [math]h = 1[/math], то мы прогнозируем на 1 шаг вперед (то есть на завтра, если время измеряется в днях).
Пример: [math]\hat{y}_{t+1}[/math] — это прогноз на завтра.
Лаги: прошлое в настоящем
Лаг — это просто задержка во времени. Представь, что ты смотришь на сегодняшнюю температуру, но тебе также важно знать, какая она была вчера или позавчера, чтобы сделать прогноз на завтра. Лаг показывает, как прошлые данные влияют на текущее или будущее.
Лаг обозначается как [math]y_{t-k}[/math], где [math]k[/math] — это число шагов назад.
- [math]y_{t-1}[/math] — это лаг на один шаг назад, вчера.
- [math]y_{t-2}[/math] — лаг на два шага назад, позавчера.
Дифференцирование: как считать изменения
Дифференцирование позволяет вычислить изменения между значениями временного ряда:
Первый порядок: [math]y'_t = y_t - y_{t-1}[/math]
Второй порядок: [math]y''_t = y_t - 2y_{t-1} + y_{t-2}[/math]
Задачи, связанные с временными рядами
Анализ временных рядов решает несколько ключевых задач в области анализа данных и машинного обучения. Эти задачи могут быть как самостоятельными, так и вспомогательными для решения других проблем. Они применимы как к отдельным временным рядам, так и к их наборам, что открывает возможности для более глубокой и детализированной аналитики.
Задачи для одного временного ряда
1.Прогнозирование
На основе данных одного временного ряда можно предсказывать его будущее поведение. Это важно для таких задач, как прогнозирование продаж, изменения цен, спроса на услуги, уровня температуры и т. д. Прогнозы могут иметь различные формы, но обычно они стремятся приблизить некоторое статистическое распределение значений [math](y_{t+h})[/math]. Основные типы прогнозов:
Точечный прогноз
Самый простой случай, когда требуется узнать конкретное значение показателя в зависимости от периода. Популярные модели, такие как ARIMA
Прогноз изменчивости
Здесь под изменчивостью обычно подразумевают прогноз дисперсии и производных от неё показателей. Примером может служить прогнозирование волатильности на фондовом рынке. Волатильность отражает степень колебаний цен на активы и является важным показателем риска для инвесторов.
Интервальный прогноз
Этот тип прогноза является комбинацией двух предыдущих. Задача заключается в предсказании интервала, в который попадёт [math](y_{t+h})[/math] с заданной вероятностью (например, 95%). Для этого требуется либо знать закон распределения [math](y_{t+h} \mid [/math][math](y_t)_{t=1}^T)[/math], либо уметь рассчитывать квантиль.
Некоторые модели, такие как ETS
2.Поиск аномалий
Анализ временных рядов помогает выявлять аномальные события — необычные или неожиданные отклонения от нормального поведения. Например, это может быть отклонение в финансовых транзакциях, сигнализирующее о мошенничестве или сбое в системе.
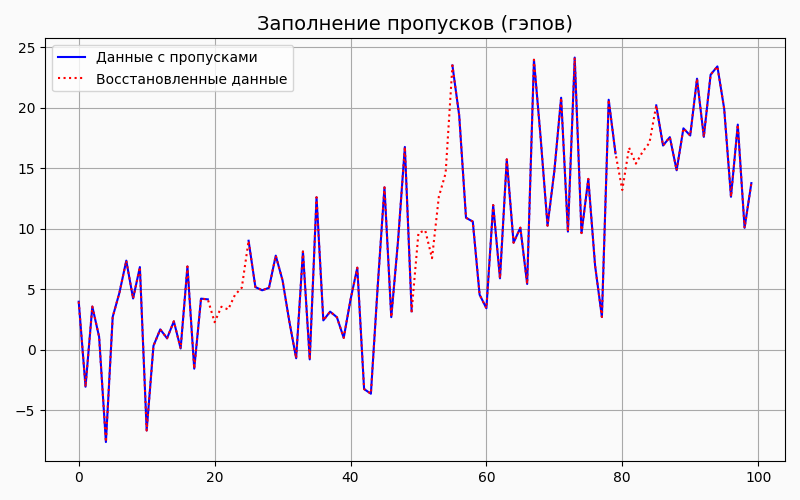
3.Заполнение пропусков (гэпов1)
Временные ряды часто содержат пропуски в данных (например, из-за сбоя измерений). Важной задачей является корректное восстановление отсутствующих значений на основе доступных данных.
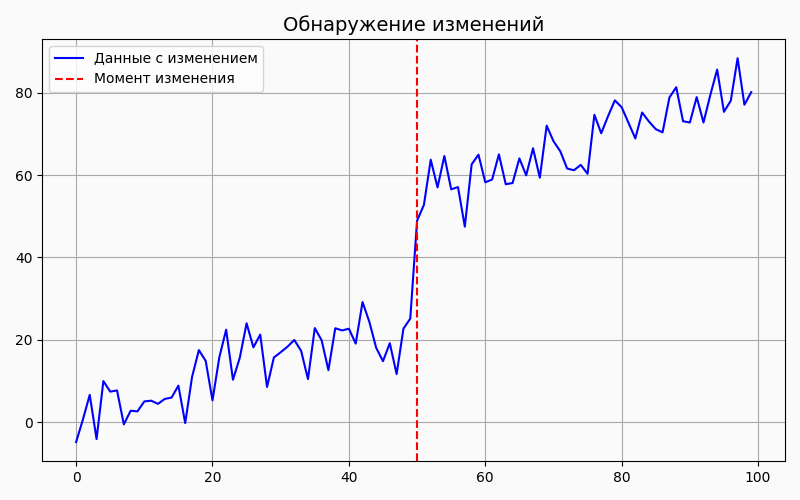
4.Обнаружение изменений
Анализ временных рядов позволяет выявлять моменты резких изменений в поведении метрики. Это полезно для диагностики проблем или отслеживания изменений в системе, например, резких изменений уровня продаж или нагрузки на сервер.
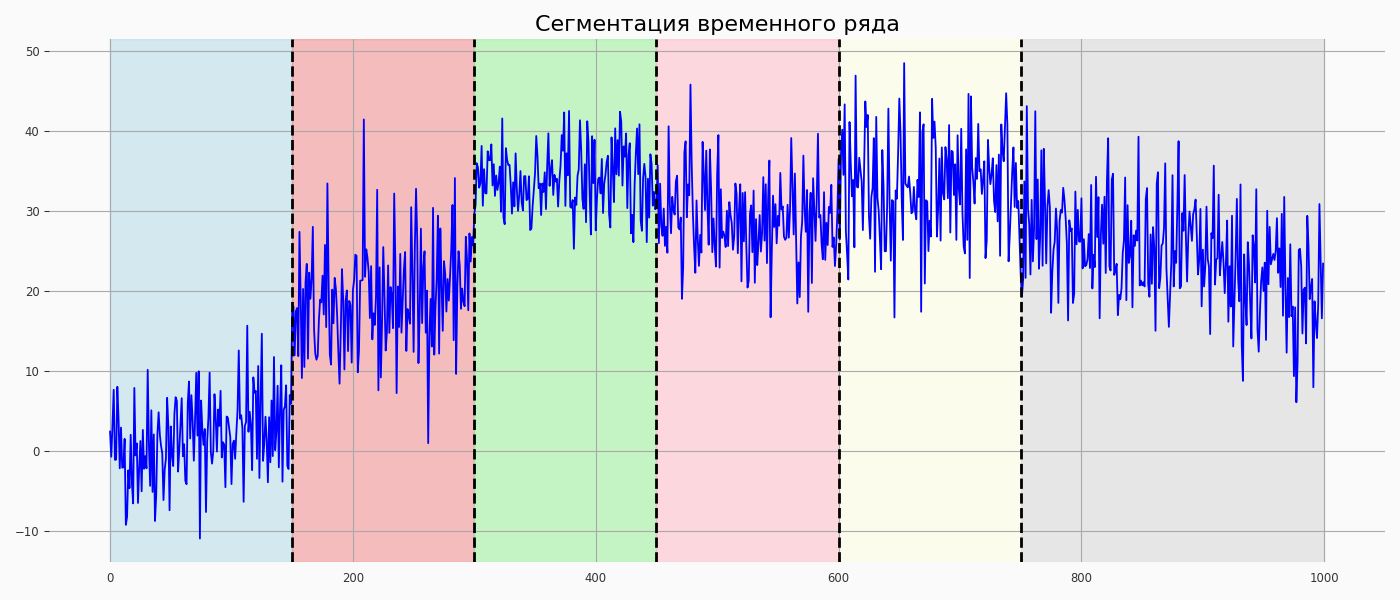
5.Сегментация временного ряда
Сегментация - это задача разделения временного ряда на отдельные фрагменты, которые характеризуются различными паттернами поведения. #ruptures
Задачи для набора временных рядов
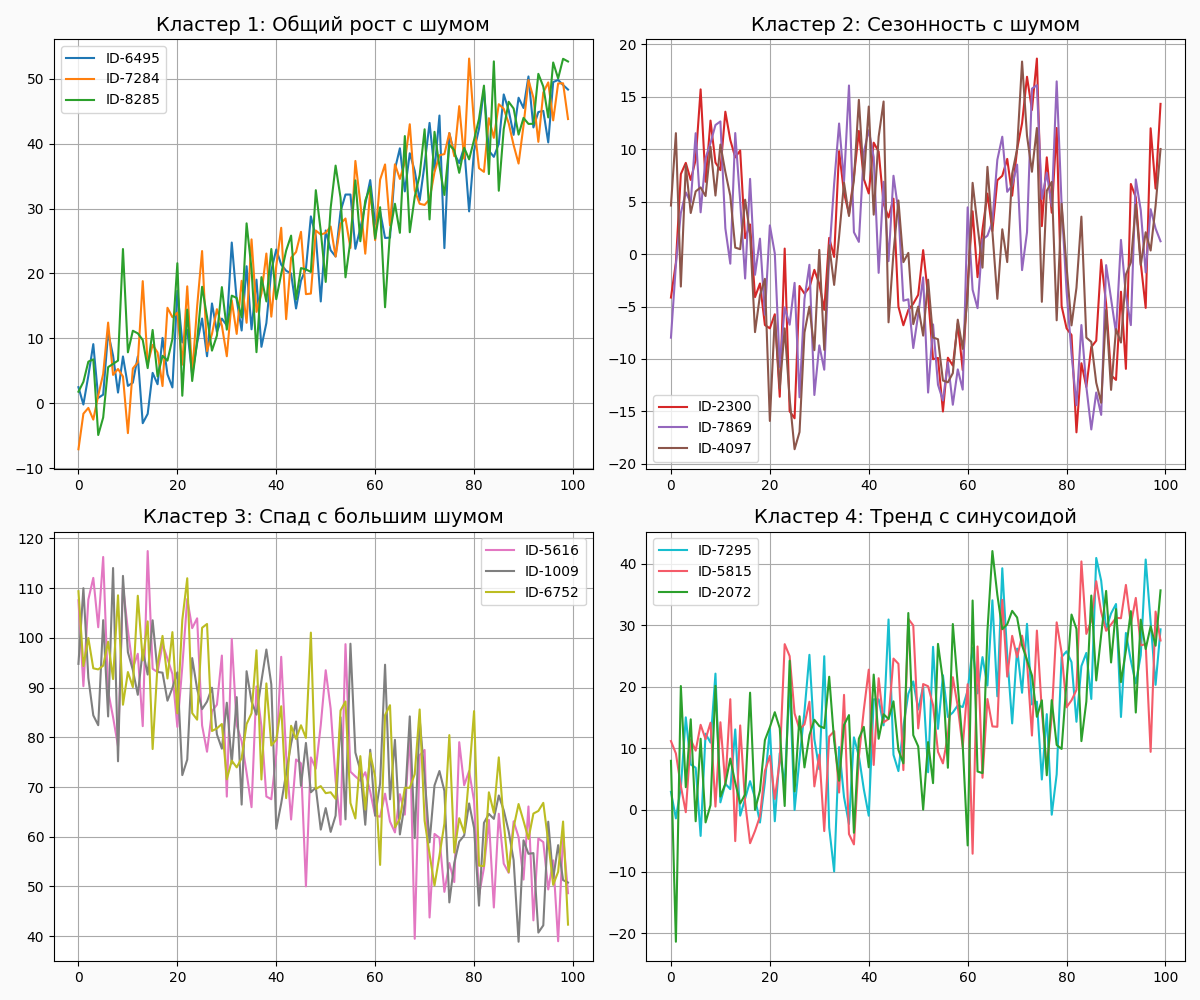
1.Кластеризация
Набор временных рядов можно использовать для группировки объектов с похожими паттернами поведения. Например, можно разделить пользователей по расходам или активности в разные временные интервалы, что позволяет лучше понять их предпочтения или выявить сегменты рынка.
2.Классификация
На основе набора временных рядов можно классифицировать объекты по типу их поведения во времени. Например, анализ временных рядов поведения клиентов в течение дня помогает классифицировать их как активных или пассивных пользователей.
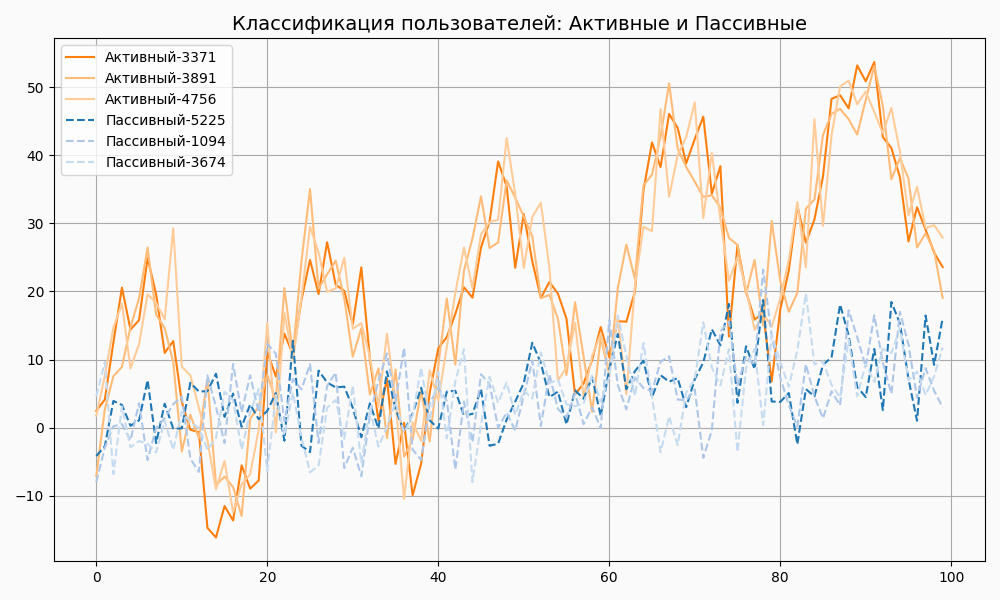
3.Создание признаков для моделей
Временные ряды могут использоваться для создания признаков features
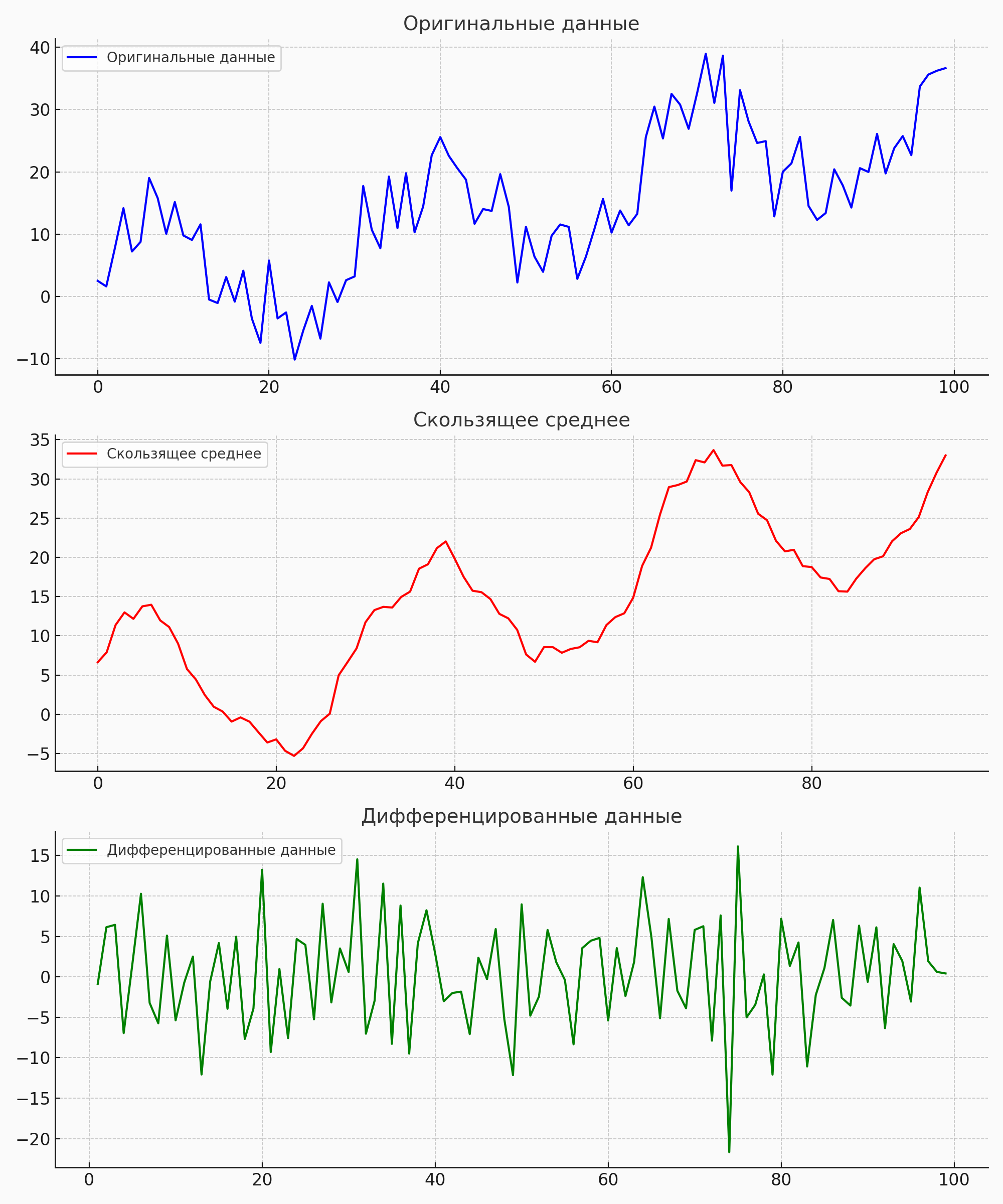
4.Обнаружение зависимостей
В наборе временных рядов можно выявлять взаимосвязи между различными показателями. Это может быть полезно для анализа финансовых рынков, когда поведение одного актива зависит от поведения другого.
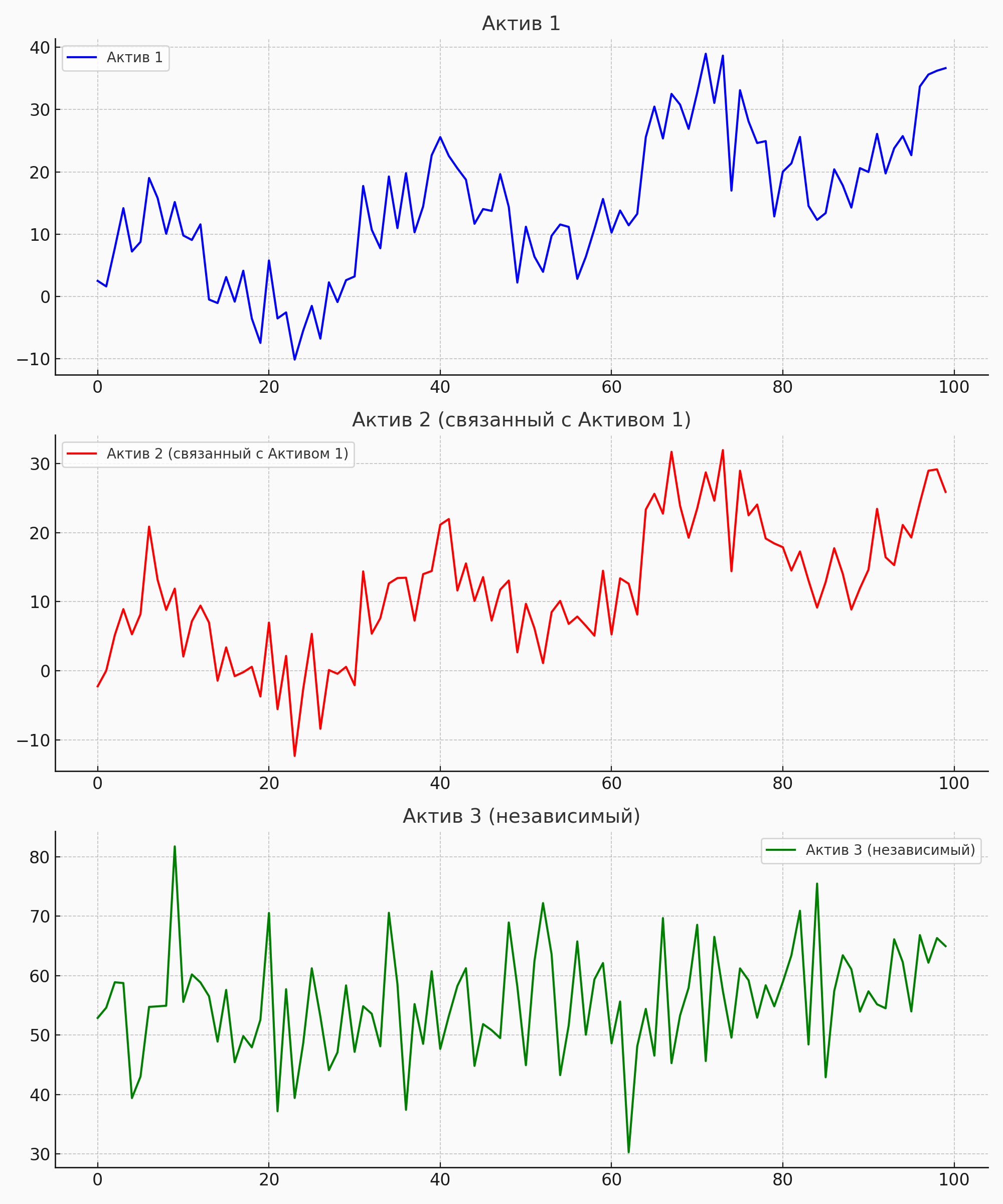
Таким образом, задачи анализа временных рядов являются разнообразными и могут применяться как к отдельным рядам, так и к целым наборам данных. Это расширяет возможности использования методов временного анализа в различных областях, таких как экономика, финансы, прогнозирование спроса, и многое другое.
Работа с временными рядами
Эндогенная и экзогенная переменная
При работе с временными рядами часто встречаются понятия «эндогенные»«экзогенные»
В библиотеке Statsmodels в Python эти переменные обозначаются как endogexogXXendogexog
Однако при переходе к разработке модели прогнозирования, важно учесть ещё один ключевой аспект — горизонт прогнозирования.
Горизонт прогнозирования
Горизонт прогнозирования определяет, на какой период в будущее мы планируем получать прогнозы, и напрямую влияет на точность и стабильность результатов модели. Правильный выбор горизонта прогнозирования — это баланс между необходимостью заглянуть далеко вперёд и сохранением приемлемого уровня точности прогноза.
Например, если горизонт прогнозирования слишком велик, модель может начать терять точность из-за увеличивающейся неопределённости. С другой стороны, слишком малый горизонт может ограничивать ценность прогнозов для принятия стратегических решений. Поэтому при проектировании модели и выборе признаков важно учитывать не только экзогенные данные, но и оптимальный горизонт прогнозирования, чтобы максимизировать надёжность и практическую пользу ваших прогнозов.
Также важным аспектом является гранулярность данных, используемых для прогнозирования. Гранулярность определяет уровень детализации временного ряда и временной интервал между наблюдениями.
| Частота ряда | Минута | Час | Сутки | Неделя | Месяц | Квартал | Год |
|---|---|---|---|---|---|---|---|
| Ежегодный | 1 | ||||||
| Ежеквартальный | 4 | ||||||
| Ежемесячный | 3 | 12 | |||||
| Еженедельный | 4.348125 | 13.044375 | 52.1775 | ||||
| Ежедневный | 7 | 30.436875 | 91.310625 | 365.2425 | |||
| Ежечасный | 24 | 168 | 730.485 | 2191.455 | 8765.82 | ||
| Ежеполучасный | 48 | 336 | 1460.97 | 4382.91 | 17531.64 | ||
| Ежеминутный | 60 | 1440 | 10080 | 43829.1 | 131487.3 | 525949.2 | |
| Ежесекундный | 60 | 3600 | 86400 | 604800 | 2629746 | 7889238 | 31556952 |
Например, данные могут быть собраны с дневной, недельной, месячной или годовой частотой. Правильный выбор гранулярности зависит от задачи
Одномерные и многомерные временные ряды
Одномерные временные ряды
Одномерные временные ряды — это данные одной переменной, измеряемые в разные моменты времени. Например, температура воздуха каждый день, цена акций каждый час, количество пользователей на сайте каждую минуту. Это просто один набор чисел, который меняется со временем. Одномерные ряды хороши для анализа одной конкретной метрики, выявления трендов и прогнозирования будущего.
Для анализа одномерных временных рядов используются такие методы, как скользящее среднее, ARIMA и экспоненциальное сглаживание. Эти методы помогают находить паттерны в данных и делать прогнозы.
Многомерные временные ряды
Многомерные временные ряды включают несколько переменных, которые измеряются одновременно. Например, можно анализировать сразу несколько показателей экономики — инфляцию, процентные ставки и ВВП. Все эти переменные взаимосвязаны и изменяются со временем. Или, например, в медицине — одновременно отслеживать пульс, давление и уровень сахара в крови пациента.
Многомерные временные ряды сложнее анализировать, потому что надо учитывать взаимосвязи между несколькими переменными. Для работы с такими рядами применяются модели типа VAR (векторная авторегрессия), которые могут учитывать влияние одной переменной на другую.
Как уже поняли, главное отличие между одномерными и многомерными рядами — это количество переменных. Одномерные ряды — это когда анализируем одну метрику. Многомерные — когда сразу несколько.
Равномерно и неравномерно распределенные временные ряды
Временные ряды можно также разделить на равномерно и неравномерно распределенные в зависимости от того, как часто данные собираются во времени.
Равномерно распределенные временные ряды
Равномерно распределенные временные ряды — это когда данные собираются через одинаковые интервалы времени. Например, каждые 5 минут, каждый час или каждый день. Такие данные легко анализировать, потому что между измерениями нет пробелов и каждое наблюдение находится на определённом месте во временной шкале.
Примером равномерных рядов может быть температура воздуха, измеряемая каждый час, или количество пользователей, заходящих на сайт каждые 15 минут. Такие ряды удобны для стандартных аналитических методов и позволяют легко выявлять тренды и закономерности.
Неравномерно распределенные временные ряды
Неравномерно распределенные временные ряды — это когда данные собираются не через равные промежутки времени. Например, события фиксируются тогда, когда они происходят, и интервалы между событиями могут быть разными. Примером могут служить звонки в службу поддержки, которые поступают в случайные моменты времени, или землетрясения, которые случаются нерегулярно.
Анализ неравномерных временных рядов более сложен, потому что временные промежутки между измерениями разные. Это требует дополнительных методов обработки данных, например, интерполяции, чтобы преобразовать данные в равномерный формат, или специальных методов анализа, таких как модели на основе событий, в python - это traces. В некоторых случаях данные просто анализируются как есть, учитывая неравномерность, чтобы лучше понять природу происходящих событий.
Компоненты временного ряда
Временной ряд, как мы уже узнали представляет собой последовательность наблюдений, собранных в определённые моменты времени, и он свою очередь может содержать несколько ключевых компонентов, каждый из которых играет свою роль в анализе данных.
Рассмотрим основные компоненты временного ряда:
Тренд
Сезонные колебания (сезонная компонента)
Примеры сезонных колебаний:
- Годовой: Продажи новогодних товаров увеличиваются в декабре и снижаются после праздников в январе.
- Месячной: Увеличение числа туристов в прибрежных городах в летние месяцы (июнь-август) по сравнению с зимними.
- Недельной: Снижение числа покупателей в супермаркетах по понедельникам после выходных и рост в выходные дни.
- Дневной: Увеличение трафика на сайтах электронной коммерции в вечерние часы по сравнению с утренними.
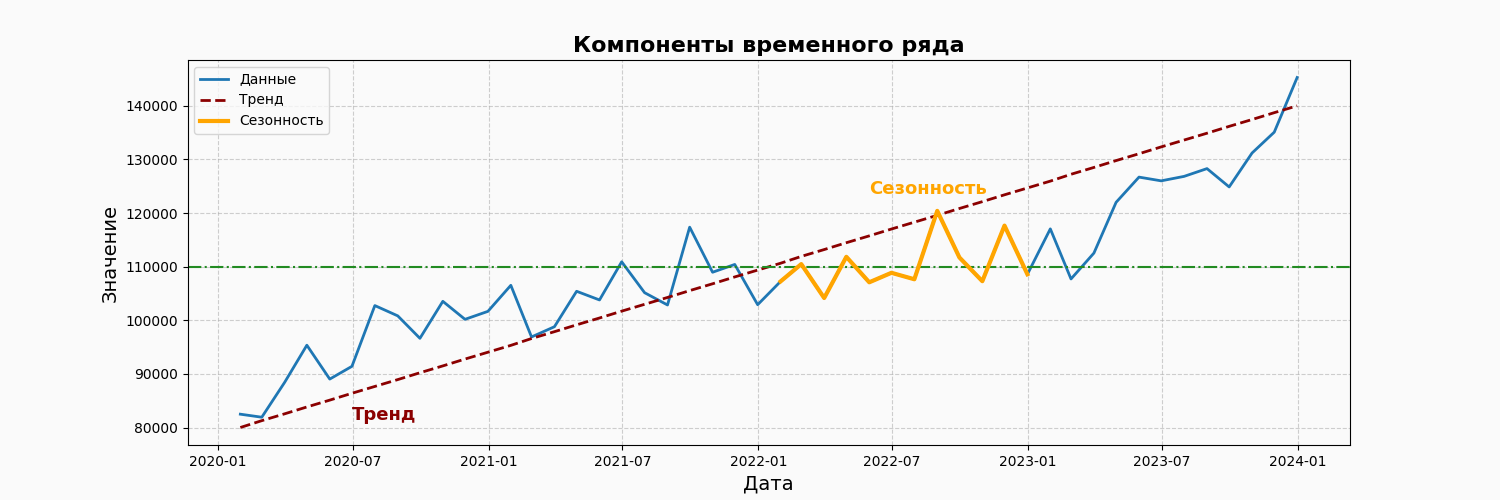
Циклические колебания (или циклическая компонента)
Примеры циклических колебаний:
- Экономический цикл: Увеличение и снижение производства в стране в течение фаз экономического роста и рецессии.
- Циклы цен на нефть: Изменения цен на нефть, которые могут колебаться в зависимости от глобального спроса и политических факторов, повторяясь каждые несколько лет.
- Циклы в аграрном секторе: Колебания производства сельскохозяйственных культур в зависимости от изменения рыночного спроса и цен, которые могут проявляться в течение нескольких сезонов.
- Циклы в потребительских расходах: Изменения в расходах потребителей, которые могут повторяться в зависимости от экономических условий, например, рост расходов во время экономического подъема и их снижение во время спада.
Случайные колебания (или нерегулярные колебания, шумы)
Резюмируя временной ряд состоит из четырех основных компонентов: тренд, который отражает долгосрочные изменения; сезонные колебания, возникающие в регулярные периоды; циклические изменения, связанные к примеру с экономическими циклами; случайные колебания, которые непредсказуемы и нерегулярны.
Модели разложения временного ряда
Для анализа временного ряда можно использовать два основных подхода: аддитивную и мультипликативную модели разложения, т.к. связано это с тем, что тренд и сезонные колебания могут проявляться как в аддитивной, так и в мультипликативной формах.
Аддитивная модель
Мультипликативная модель
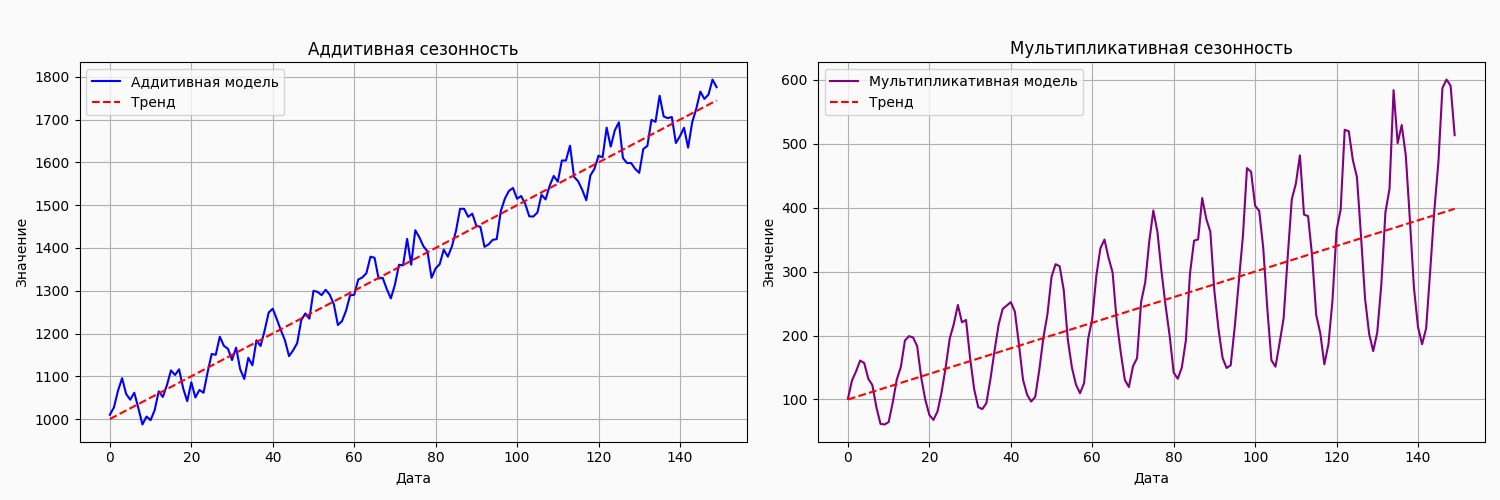
Выбор между аддитивной и мультипликативной моделью зависит от характера данных и от того, как компоненты взаимодействуют друг с другом. Так, если сезонные колебания усиливаются с ростом тренда, более уместна будет мультипликативная модель, а аддитивная модель применима в тех случаях, когда амплитуда сезонных колебаний в ряду остается постоянной.
В итоге, временные ряды – это последовательности измерений, где взаимосвязь между прошлыми и будущими значениями позволяет строить прогнозы, выявлять аномалии и определять закономерности. На этом мы остановимся, чтобы закрепить полученные знания, а дальнейшее погружение в практические методы и примеры анализа временных рядов продолжим в следующих статьях.
- Гэпы (от англ. "gaps") в данных — это пропуски или отсутствующие значения в наборе данных. ↩︎
Пройдите квиз по этой статье
Чтобы закрепить пройденный материал
Квиз генерируется нейросетью. Эта модель отлично работает с длинным контекстом, рассуждениями и логикой, но иногда ошибается (как и все нейросети).
 помощник
помощник